
本小组成员高雄同学的技术论文《MSLWENet: A Novel Deep Learning Network for Lake Water Body Extraction of Google Remote Sensing Images》被国际知名期刊《Remote Sensing》接收并在线发表!

在我们赖以生存的地球表面大约有3.04亿个天然湖泊,覆盖了460万公里的水域。青藏高原是地球上湖泊面积最大、数量最多和海拔最高的高原内陆湖区,也是我国湖泊分布密度最大的两个稠密湖区之一。一方面,湖泊对全球温度变化非常敏感并且在二氧化碳循环中发挥重要作用。另一方面,湖泊还有发展畜牧业、提供水源和交通航运的功能。
以前对湖泊水体提取的研究主要分为阈值法和机器学习方法。然而,阈值法中寻找最佳阈值将耗费大量的时间和计算量,机器学习方法则依赖人工设计的特征。近日,我们完成了一项研究,采用深度学习语义分割算法实现了青藏高原湖泊水体的自动提取,与一系列用于自然图像分割算法相比,我们的算法在五项评价指标中都取得了最优异的性能。解决了湖泊类内方差大、类间方差小和小湖泊水体提取的问题,该研究为我们对青藏高原湖泊进行有效规划、保护和预防灾害发生有重要的意义。
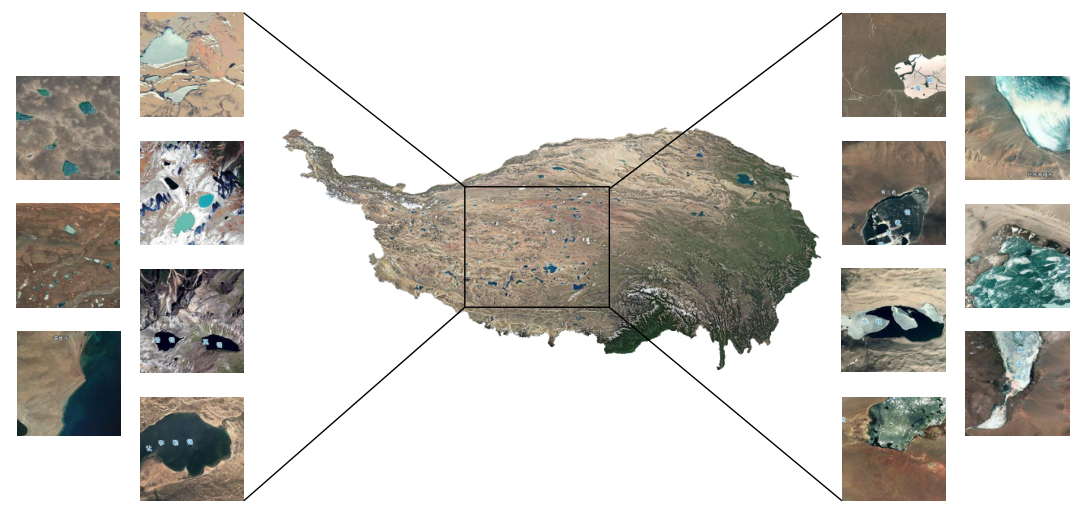
本项研究主要是在青藏高原上进行,如图1所示,湖泊在光谱特征上呈现白色、淡蓝色、深蓝色和黑色,在种类上又分为盐湖和淡水湖,在状态上又呈现为冻湖、半冻湖和未冻湖,而且山和云的阴影积雪又与湖泊具有相似的特征,这大大增大了我们研究的难度。
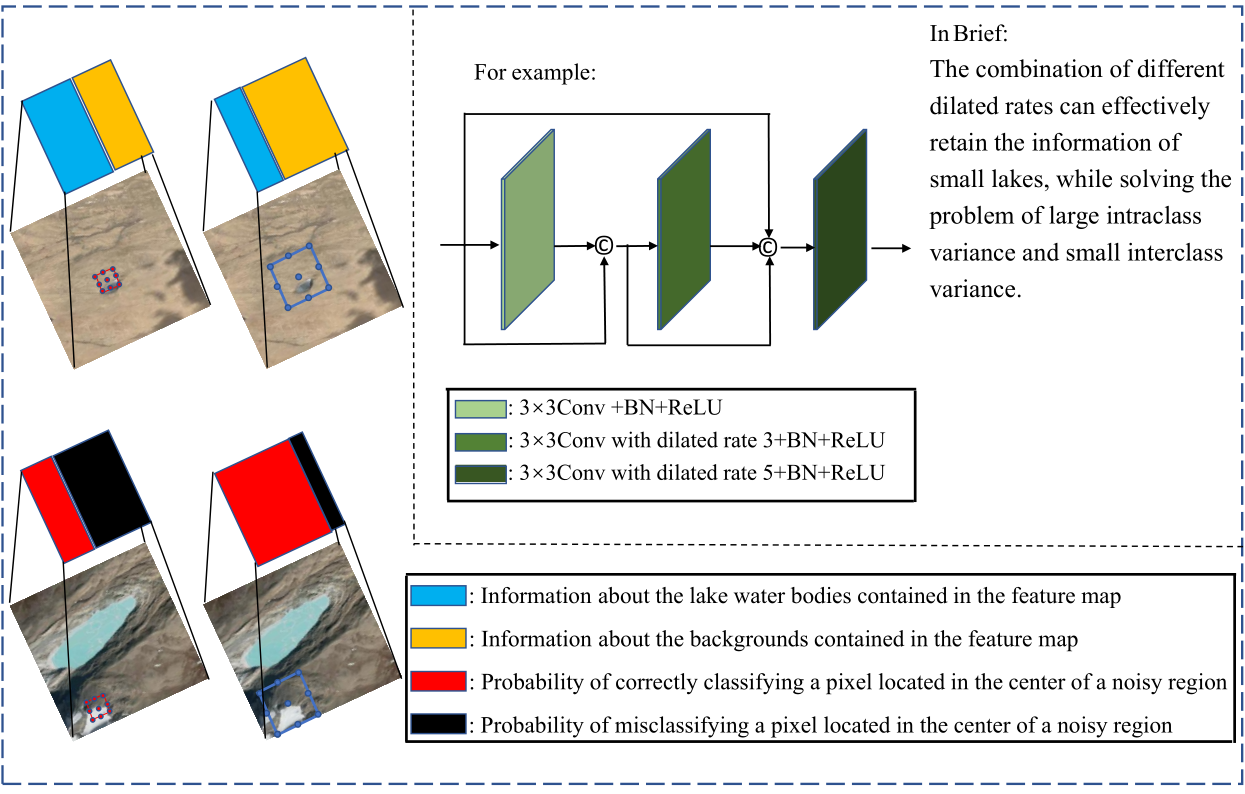
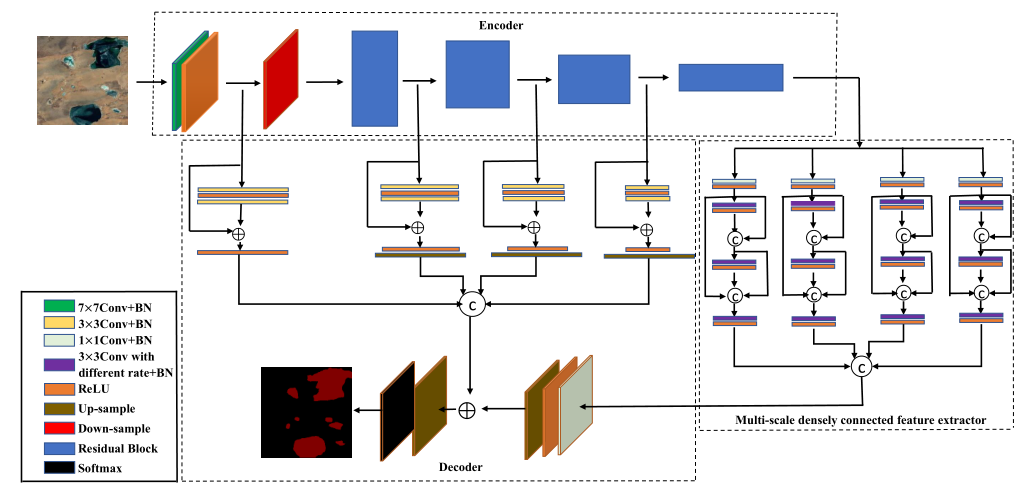
如图2所示,小的空洞卷积可以有效地保留小水体的信息,但是不能正确分类位于噪声干扰区域的像素,大的空洞卷积可以正确分类像素,但是会造成有用信息的丢失,为了解决上述问题,我们设计了多尺度密集连接特征提取器。采用逐渐扩大的空洞卷积来使特征点的感受野更大更密集,为了提高小湖泊水体提取的准确性,在每次空洞卷积之前,将特征图与之前层的特征进行通道连接,来获取更详细的上下文信息。在编码器阶段,我们用ResNet-101作为主干网络,由于湖泊数据集较小,为了防止模型过拟合,引入了深度可分离卷积来降低模型的参数量。编码器的浅层特征层包含湖泊的位置和边界等特征,深层特征层含有湖泊的语义特征,浅层特征层的复用,可以有效的提高边界分割的准确性。在解码器部分,我们使用残差卷积来抽象编码器的不同特征层的特征,并使用通道连接将不同水平的特征整合到一起,使用上述策略可以较准确地实现湖泊水体的提取,模型的具体结构如图3所示。
原文链接:https://www.mdpi.com/2072-4292/12/24/4140/pdf
( 发布日期: 2020-12-22 )
